ビッグデータ可視化
ビッグデータ可視化は、セルフサービス分析においてあらゆるデータサイエンティストやビジネス・ユーザーにとって目下の課題です。 Viscoveryマップは、革新的な可視化だけでなく、データ探索、クラスタリング、統計的プロファイリングのための実績のある手法を提供します。
目的
アメリカ合衆国の2250万件の死亡記録のデータセットを用いて、 Viscovery SOMineでどのようにしてビッグデータが素早く可視化できて、分析できるかをお見せします。
Viscoveryのこの新機能は、大きなデータ・サンプルでは、データ分布が全体のデータセットの分布にとても相似であるという事実に基づきます(下のスクリーンショットを比較してください)。したがって、 Viscoveryマップを作成するのにはデータのサンプルを使用するので十分です。そして、マップに全体のデータセットをマッチさせることができます。
結果のモデルがエクスポートできて、すべての(マイクロな)統計情報を含み、全体のデータセットの元のレコードにリンクできます。これは、全データセットからマップを訓練する必要なく、Viscoveryマップを通してビッグデータセットに直接アクセスし、探索することを可能にします。
– version 7.1 から利用可能な– 新機能は、任意のレコード数のデータセットに適用可能で、ビッグデータへのインタラクティブなデータ探索の世界を開きます。 データセットの基本的な要件は、それが正規化解除された表として利用可能なことです。


Viscoveryマップと計算時間の比較: 5% サンプル、1.2 時間(左); 全データセット, 24.5 時間 (右)
アドバンテージとベネフィット
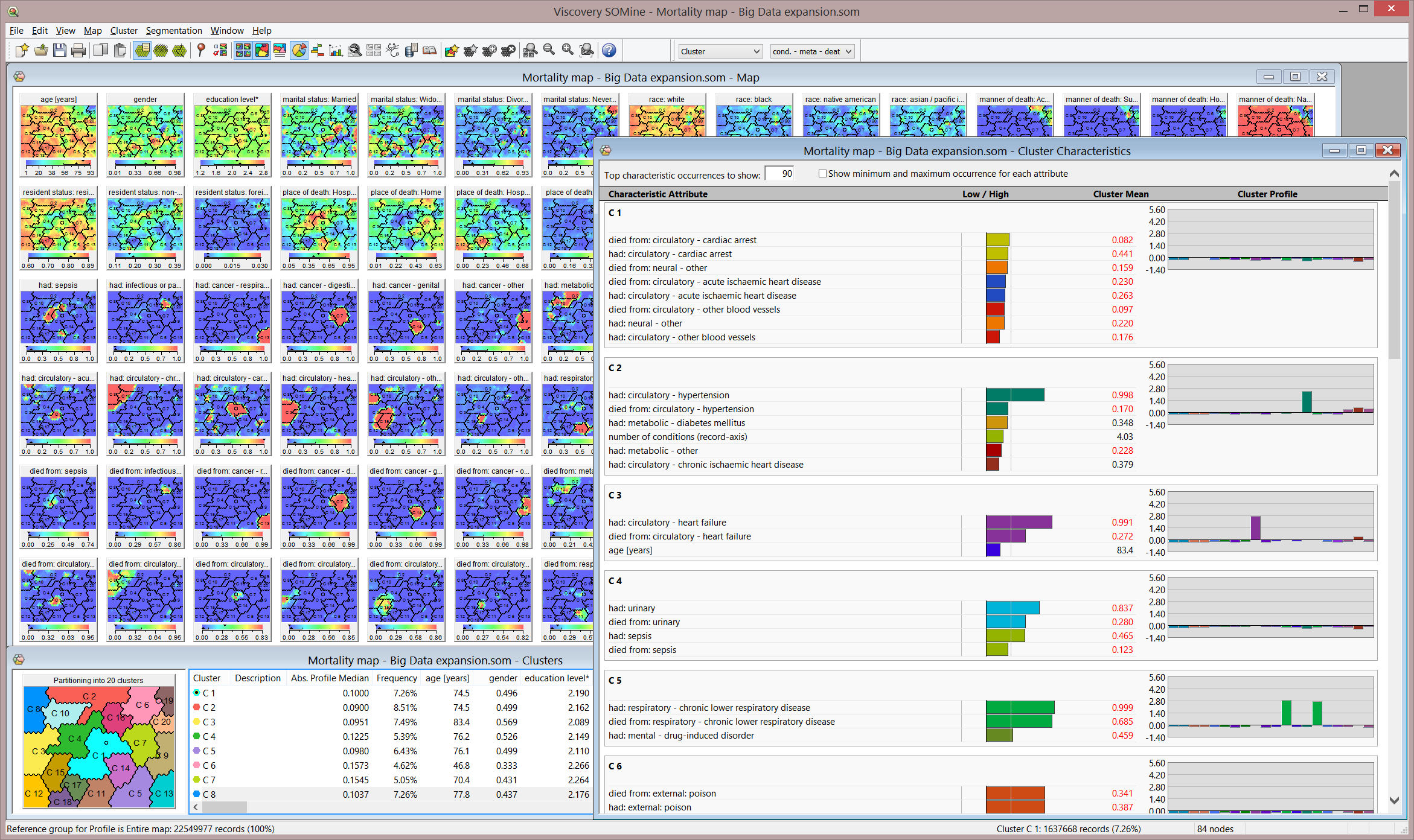
マップ可視化は、任意の領域選択の記述統計を瞬時に提供し、元のデータレコードへのリアルタイム・アクセスを可能にします。即座の計算のための高度な統計量が利用可能です。とても大規模なデータセットでも、ほんの数秒で クラスタ と統計的 プロファイル を作成、修正、判断するできます。
この新機能によって、マップの計算に時間がかかり過ぎると予想される場合でもビッグデータへのビジュアル・アプローチを提供します。 したがって、計算時間が2桁削減されます。インタラクティブなクラスタリング、探索およびプロファイリング機能は、意思決定やアクションをマップから直接派生させることを可能にします(下のスクリーンショットを参照)。
データソースと謝辞
データセットはNational Bureau of Economic Research からのもので、1959年からのアメリカ合衆国での死亡証明に関する情報を含みます。我々は、 2006年から 2014年までのデータ(合計 22,549,978レコード)を使用しました。これは2006年以前のデータは、データ構造が異なるからです。
各死亡記録は、人に関するデータ(たとえば、年齢、性別、教育)、死亡の方法(自然、事故、自殺、他殺)、死亡の原因(たとえば、脳内出血、乳癌、負傷、被毒)、および死亡診断で言及された健康状態、死亡に関する特有のメタデータ(たとえば、死亡の場所、死亡の曜日、剖検)を含みます。
データ前処置
Viscoveryの前処理ワークフローで、下記の前処理ステップが実行されました。
変数 Detail Age は満年齢を得るためにデコードされました。オリジナル・データセットの変数 Education (1989年版) とEducation (2003 年版)は、education levelという単一の属性に統合されました。死亡前にまだ学校を卒業していなかった未成年者に関しては、この変数を欠損値に設定しました。
ICD10 コーディング・スキームで死亡診断に記載された詳細な健康状態を記述している変数 enicon_1 から enicon_20は、had という多項属性にまとめられました。 ICD10スキームでの数千種類のコードが、主要な 疾患クラスと死亡原因を反映する 30 個の意味のわかるカテゴリにグループされました(たとえば、感染症、癌、脳血管疾患、事故)。死亡の根本原因を記述する died from 属性に関しては、同じグループが使用されました。
Viscoveryマップの作成
Viscoveryの クラスタ・ワークフローを用いて、全データセットの5 % サンプル(1,135,798 レコード)からViscoveryマップが作成されました。次の属性重要度が使用されました: ageに1.0、 gender と education levelに 0.4、 hadに0.25、 marital status と raceに 0.1。分散/範囲スケーリングに関しては、 Viscoveryのデフォルトのメカニズムが使用されました。
マップは、 “自動のマップ・フォーマット”の約1000ノードで訓練されました。トレーニング・スケジュールは “Accurate” でテンションを 0.5としました。 Viscovery SOMineの分類ワークフローを実行して、全データセットがマップに割り当てられました。 モデルの適用ステップを完了後、名前を付けてコピーを保存で拡張モデルがエクスポートされました。.
全データのモデルとのマップ比較のために(右のスクリーンショット)、サンプル・データと同じパラメータが使用されました。
